

Use Cases
Coding agents can flexibly automate multi-step manual workflows and conduct investigations in parallel. Try:- Comparing between checkpoints. Suppose you want to answer questions like “What caused a regression between checkpoint A and checkpoint B?” or “These two checkpoints show a quantitative tradeoff on eval scores. What behaviors might explain that?” Prompting the agent to compare pairs of successful and failed runs helps identify changes between multiple versions of a model. See a detailed tutorial below.
- Triaging before deep analysis: Improve cost-efficiency by focusing your expensive classifier runs. Prompt your agent to:
- Do a first pass with a cheap model for tagging possible issues (“sycophancy,” “copyright,” “biorisk,” etc), conservatively including potential false positives
- Then use a more expensive model with detailed, issue-specific rubrics over only the relevant parts of the collection. Assign a detailed sycophancy classifier to run over the transcripts tagged “sycophancy” and a copyright classifier to run over the transcripts tagged “copyright.”
- Managing long context: Flexibly control context when analyzing collections with long traces or many transcripts. To summarize failures across a large collection, your agent can batch transcripts, extract key observations from each batch, and then clustering and observe patterns from the batched observations. Recursively passing the results from previous analyses improves your agent’s ability to handle collection-level queries at scale.
Quickstart
We recommend using our Claude Code plugin so you can quickly install updates to the plugin. However, we also support using Docent in its own Cursor Workspace by quickly downloading our template and integrating Docent into an existing workspace. In either case, you’ll need to have uv installed.- Claude Code Plugin (Recommended)
- From Template
- Existing Workspace
Install Claude Code and open it in your working directory by running Install the Docent plugin:Restart Claude Code after installation. Type
claude. Run the following inside of Claude Code.Add the Transluce plugin marketplace:/ to verify that /ingestion and /analysis are available.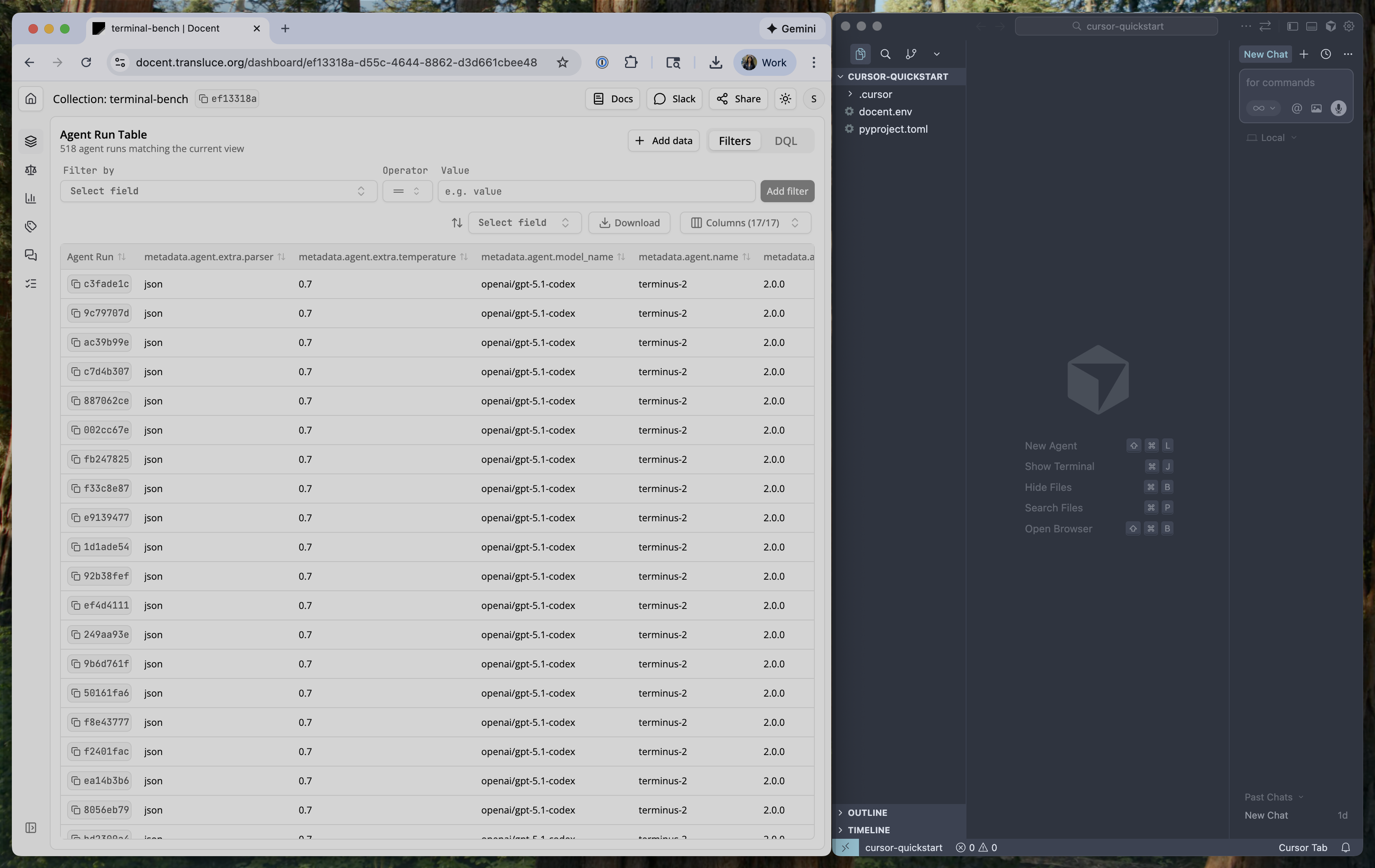
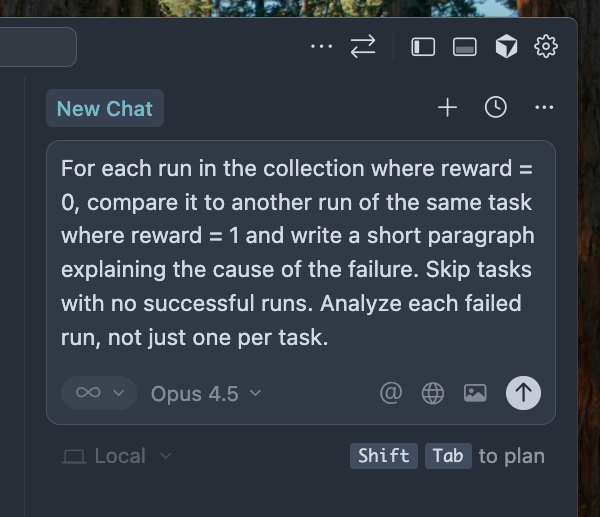
Using Docent to Compare Between Checkpoints
See a demo of this plugin on our blog. We used the analysis skill to diagnose why GPT-5.1 Codex underperforms GPT-5 Codex on Terminal-Bench.
For each run in the collection where reward = 0, compare it to another run of the same task where reward = 1 and write a short paragraph explaining the cause of the failure. Skip tasks with no successful runs. Analyze each failed run, not just one per task.After checking the structure of the relevant metadata, the agent might write something like this:
Generated script: Compare failed runs to successful runs
Generated script: Compare failed runs to successful runs
Make a new script to group these results by the agent of the run being analyzed. Then look at all the results, grouped by agent, and summarize the differences in failure modes between the models
Generated script: Summarize failure modes by model
Generated script: Summarize failure modes by model
Best Practices & Future Work
- When selecting a model for your coding agent, Claude Sonnet 4.5 is a good place to start. Smaller models often get confused about various aspects of the analysis workflow.
- For best results, be precise when telling the coding agent what workflow you want to execute.
- The LLM can only cite items that were directly passed as part of the prompt. It cannot, for example, cite items that were cited by a result that was passed as part of the prompt. If the LLM gets confused about this fact, mention it in your prompt. We’re working on a cleaner solution.
- We’re currently adding functionality to analyze Docent judge results. Stay tuned!